In the ever-evolving landscape of large language models, SmallStep AI takes a significant stride forward with the introduction of Misal 7B and 1B. These pre-trained and instruction-tuned models are tailored specifically for Marathi, contributing to the broader effort of enhancing multilingual abilities in AI systems.

The development of Misal stems from the recognition of limitations within existing models, particularly Meta’s Llama2, which was predominantly trained on English data. With only a small fraction dedicated to non-English languages, including Marathi, it became evident that a specialized solution was necessary to propel the development of GenAI applications in languages beyond English.
To address this gap, SmallStep AI embarked on the creation of Misal, a Marathi Large Language Model (LLM) fine-tuned over Meta’s Llama architecture. Today, the company unveils four distinct Misal models:
- Marathi Pre-trained LLM – Misal-7B-base-v0.1 & Misal-1B-base-v0.1
- Marathi Instruction-tuned LLM – Misal-7B-instruct-v0.1 & Misal-1B-instruct-v0.1
A meticulous three-step process underpins the creation of the Instruction-Tuned Misal models. For Misal-7B, the journey begins with:
1. Tokenizer Enhancement:
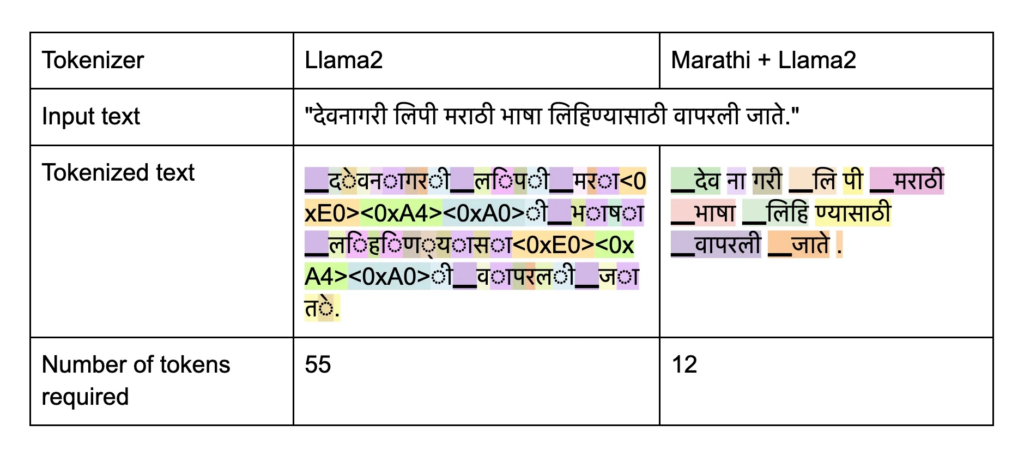
Meta’s Llama tokenizer faced challenges in representing non-English languages efficiently, particularly Marathi, due to the increased number of tokens required. To overcome this hurdle, SmallStep AI opted to train a specialized SentencePiece tokenizer for Marathi. This initiative resulted in the incorporation of nearly 15,000 new tokens, complementing the existing 32,000 tokens of Llama2.
2. Pretraining Phase:
The pretraining phase saw Misal exposed to a diverse corpus of Marathi text data, encompassing approximately 2 billion tokens. This corpus, sourced primarily from newspaper archives spanning 2016 to 2022, was augmented with supplementary data from sources such as l3cube, ai4bharat, and other internet-based datasets. This comprehensive training regimen ensured that Misal was equipped with a nuanced understanding of Marathi language patterns and nuances.
3. Fine-tuning for Instruction:
Building upon the robust foundation laid during pretraining, the Misal models underwent fine-tuning for specific instructional purposes. This process involved tailoring the models to excel in particular tasks or domains, enhancing their efficacy and adaptability across a range of applications.
SmallStep AI’s unveiling of the Misal models marks a significant milestone in the journey towards democratizing AI for diverse linguistic contexts. By addressing the inherent challenges in multilingual model development, Misal paves the way for the creation of innovative GenAI applications tailored to the nuances of the Marathi language.
With Misal, SmallStep AI reaffirms its commitment to advancing the frontiers of AI research and development, empowering creators and innovators worldwide to harness the full potential of language models across linguistic boundaries.
