DBMS or Database Management System is a crucial subject for second-year engineering students, providing the foundation for understanding database concepts and their practical applications. This blog post aims to equip students with comprehensive viva questions and answers covering all six modules of DBMS. By thoroughly preparing for these questions, students can enhance their understanding, boost their confidence, and excel in their viva voce examinations.
Table of Contents
Module 1: Introduction Database Concepts
Q: What is a database, and what are some of its characteristics?
A: A database is an organized collection of data that is stored electronically. Some of its characteristics include: persistence (data is stored beyond the life of an application), large capacity (databases can store large amounts of data), and concurrent access (multiple users can access the database simultaneously).
Q: What is the difference between a file system and a database system?
A: A file system is a collection of files that are stored on disk and organized hierarchically. A database system, on the other hand, is designed to manage and store large amounts of data in an organized and efficient way. Databases support advanced querying and indexing, as well as data integrity and security features.
Q: What is data abstraction, and why is it important in databases?
A: Data abstraction is the process of hiding implementation details and exposing only the relevant information to users. It is important in databases because it allows users to work with data at a high level, without needing to understand the underlying details of how the data is stored and managed.
Q: What is data independence, and why is it important in databases?
A: Data independence is the ability to change the data storage or schema without affecting the applications that use the data. It is important in databases because it allows for greater flexibility and scalability, as well as easier maintenance and upgrades.
Q: What is a DBMS, and what are some of its components?
A: A DBMS (Database Management System) is a software system that is used to manage and store data in a database. Some of its components include: a data dictionary (which stores metadata about the database), a query processor (which translates user queries into instructions for the database), and a transaction manager (which ensures data integrity and consistency).
Q: What is a database administrator (DBA), and what are some of their responsibilities?
A: A database administrator (DBA) is a person who is responsible for managing and maintaining a database system. Some of their responsibilities include: designing and maintaining the database schema, ensuring data security and privacy, monitoring database performance and capacity, and performing backups and recovery operations.
Q: What are some advantages of using a database system over a file system?
A: Some advantages of using a database system include: improved data consistency and accuracy, better data sharing and concurrency, increased productivity and efficiency, and enhanced security and access control.
Q: What is a database schema, and what is it used for?
A: A database schema is a blueprint or plan that describes the structure of a database. It includes information about the tables, fields, and relationships in the database. The schema is used to create and maintain the database, as well as to ensure data integrity and consistency.
Q: What is normalization, and why is it important in database design?
A: Normalization is the process of organizing data in a database to reduce redundancy and dependency. It is important in database design because it helps to improve data integrity and consistency, as well as to reduce the risk of data anomalies.
Q: What are some common data types used in databases?
A: Some common data types used in databases include: integer, decimal, string, date/time, boolean, and binary. Each data type has its own range of values and operations that can be performed on it.
Module 2: Entity-Relationship Data Model:
Q: What is the Entity-Relationship (ER) model, and how is it used in database design?
A: The Entity-Relationship (ER) model is a conceptual data model that is used to represent entities and their relationships in a database. It is used in database design to help visualize the data structure and to identify the relationships between entities.
Q: What is an entity type, and how is it represented in an ER diagram?
A: An entity type is a group of entities that have the same attributes. It is represented in an ER diagram as a rectangle, with the entity type name written inside.
Q: What is a weak entity set, and how is it represented in an ER diagram?
A: A weak entity set is an entity set that cannot be uniquely identified by its own attributes. It depends on another entity set, called its owner entity set, for identification. It is represented in an ER diagram as a rectangle with double lines, with the entity set name written inside.
Q: What is a strong entity set, and how is it represented in an ER diagram?
A: A strong entity set is an entity set that can be uniquely identified by its own attributes. It does not depend on another entity set for identification. It is represented in an ER diagram as a rectangle with a single line, with the entity set name written inside.
Q: What are the different types of attributes, and how are they represented in an ER diagram?
A: The different types of attributes include: simple, composite, and derived attributes. Simple attributes are atomic values that cannot be further divided. Composite attributes are composed of multiple simple attributes. Derived attributes are calculated based on other attributes. They are represented in an ER diagram as ovals, with the attribute name written inside.
Q: What is a key, and why is it important in entity-relationship modeling?
A: A key is a set of attributes that uniquely identifies an entity. It is important in entity-relationship modeling because it helps to ensure data integrity and to avoid data redundancy.
Q: What are relationship constraints, and how are they represented in an ER diagram?
A: Relationship constraints are rules that specify the relationships between entity sets. They include cardinality constraints (which specify the number of entities in a relationship) and participation constraints (which specify whether an entity is required or optional in a relationship). They are represented in an ER diagram using lines that connect the entity sets, with cardinality and participation notation written near the lines.
Q: What is the Extended Entity-Relationship (EER) model, and how is it different from the ER model?
A: The Extended Entity-Relationship (EER) model is an extension of the ER model that includes additional features, such as generalization, specialization, and aggregation. It is different from the ER model in that it allows for more complex relationships and hierarchies between entities.
Q: What is generalization, and how is it represented in an EER diagram?
A: Generalization is the process of creating a new entity type from existing entity types. It is represented in an EER diagram using a triangle, with the new entity type written inside. The existing entity types are connected to the new entity type using lines, with the word “is-a” written near the lines.
Q: What is specialization, and how is it represented in an EER diagram?
A: Specialization is the process of creating a new entity type from an existing entity type by adding more specific attributes. It is represented in an EER diagram using a triangle, with the existing entity type written inside. The new entity type is connected to the existing entity type using a line, with the word “is-a” written near the line. The new entity type has its own attributes, which are represented using ovals.
Q: What is aggregation, and how is it represented in an EER diagram?
A: Aggregation is the process of combining two or more entities into a single entity. It is represented in an EER diagram using a diamond, with the new entity type written inside. The existing entity types are connected to the new entity type using lines, with the word “part-of” written near the lines.
Q: How can you determine the cardinality and participation constraints in a relationship?
A: You can determine the cardinality and participation constraints in a relationship by analyzing the business rules that govern the relationship. For example, if a customer can have multiple orders, but an order can only be placed by one customer, the cardinality of the relationship would be “one-to-many” and the participation of the customer entity would be “mandatory” while the participation of the order entity would be “optional”.
Q: What is the difference between a strong and weak entity set?
A: A strong entity set can be uniquely identified by its own attributes, while a weak entity set cannot be uniquely identified by its own attributes and depends on another entity set (called its owner entity set) for identification.
Q: What is a composite attribute?
A: A composite attribute is an attribute that is composed of multiple simple attributes. For example, an address attribute may be composed of street, city, state, and zip code attributes.
Module 3: Relational Model and Relational Algebra:
Q: What is the Relational Model?
A: The Relational Model is a conceptual model used to organize data in a database. It is based on the concept of relations (tables) that are composed of tuples (rows) and attributes (columns).
Q: What is a relational schema, and what does it include?
A: A relational schema is a blueprint for the structure of a database that defines the tables, attributes, and relationships between tables. It includes the table names, attribute names, data types, and any constraints or rules.
Q: What are keys in a relational schema?
A: Keys in a relational schema are attributes that uniquely identify a tuple in a table. They are used to enforce data integrity and maintain consistency in the database.
Q: How can you map an ER or EER diagram to a relational schema?
A: You can map an ER or EER diagram to a relational schema by creating tables for each entity type, using the attributes as columns in the table, and creating foreign keys to represent the relationships between tables.
Q: What are relational algebra operators?
A: Relational algebra operators are a set of mathematical operations used to manipulate tables in a relational database. Some of the operators include union, intersection, difference, selection, projection, join, and division.
Q: What is a selection operator in relational algebra?
A: The selection operator in relational algebra is used to retrieve a subset of tuples from a table based on a specified condition.
Q: What is a projection operator in relational algebra?
A: The projection operator in relational algebra is used to select specific columns (attributes) from a table and discard the rest.
Q: What is a join operator in relational algebra?
A: The join operator in relational algebra is used to combine two or more tables based on a common attribute. It creates a new table that contains all the attributes from the original tables.
Q: What is a query in relational algebra?
A: A query in relational algebra is a sequence of relational algebra operations used to retrieve data from one or more tables in a database. The output of a query is a table that contains the results of the operations.
Q: What is the difference between union and intersection operators in relational algebra?
A: The union operator combines two tables and eliminates any duplicates, while the intersection operator returns only the common rows between two tables, without duplicates.
Module 4: Structured Query Language (SQL):
Q: What is SQL? A: SQL (Structured Query Language) is a programming language used to manage and manipulate data in a relational database.
Q: What are the types of commands in SQL?
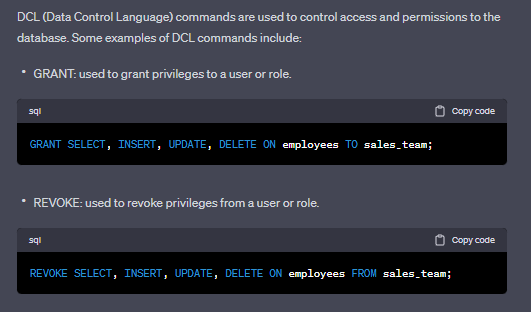
A: The types of commands in SQL are Data Definition Language (DDL) commands, Data Manipulation Language (DML) commands, and Data Control Language (DCL) commands.
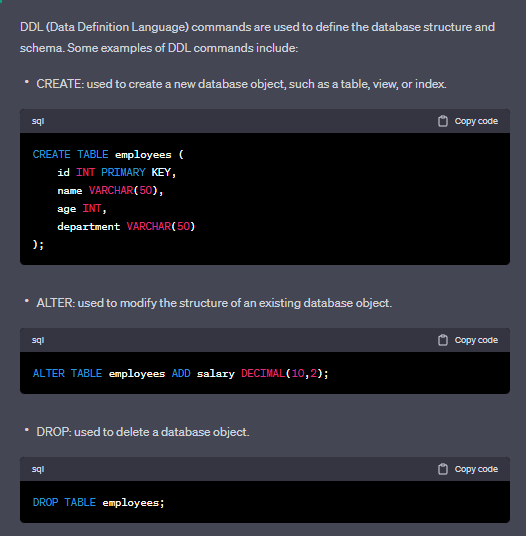
Q: What are some examples of DDL commands in SQL?
A: Examples of DDL commands in SQL include CREATE, ALTER, and DROP, which are used to create, modify, and delete database objects such as tables, views, and indexes.
Q: What are integrity constraints in SQL?
A: Integrity constraints in SQL are rules that are used to ensure data consistency and accuracy in a database. Some examples of integrity constraints are key constraints, domain constraints, and referential integrity constraints.
Q: What is the purpose of key constraints in SQL?
A: Key constraints in SQL are used to ensure that a column or set of columns in a table uniquely identifies each row. Primary key constraints and unique key constraints are examples of key constraints.
Q: What is the purpose of referential integrity constraints in SQL?
A: Referential integrity constraints in SQL are used to ensure that the relationships between tables are maintained and that data is not deleted or updated in a way that would violate these relationships.
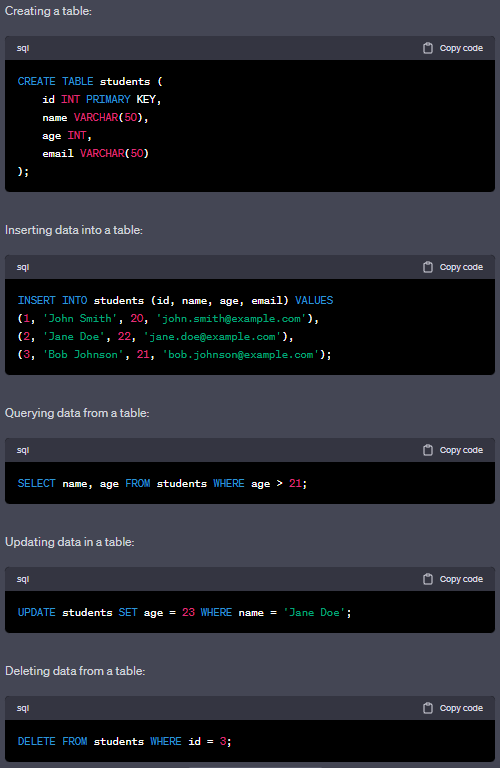
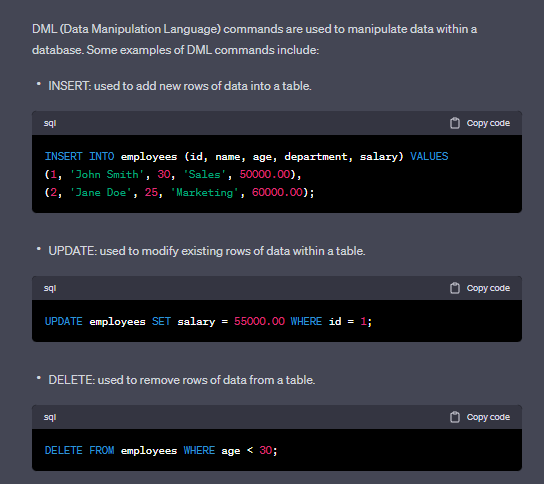
Q: What are the types of DML commands in SQL?
A: The types of DML commands in SQL are SELECT, INSERT, UPDATE, and DELETE, which are used to retrieve, add, modify, and delete data in a database.
Q: What are aggregate functions in SQL?
A: Aggregate functions in SQL are used to perform calculations on a set of values and return a single value. Examples of aggregate functions include SUM, AVG, MAX, MIN, and COUNT.
Q: What is the purpose of GROUP BY and HAVING clauses in SQL?
A: GROUP BY and HAVING clauses in SQL are used to group data and perform aggregate calculations on the groups. GROUP BY is used to group the data by one or more columns, while HAVING is used to filter the groups based on a condition.
Q: What are views in SQL?
A: Views in SQL are virtual tables that are based on the results of a SELECT statement. They can be used to simplify complex queries and provide a more user-friendly interface to the data.
Q: What is a join in SQL?
A: A join in SQL is used to combine data from two or more tables based on a common column or set of columns.
Q: What is a trigger in SQL?
A: A trigger in SQL is a special type of stored procedure that is automatically executed in response to a specific event, such as a data modification or insertion, in a database.
Module 5: Relational-Database Design
Q. What is the relational database design?
A. Relational database design is a process of creating a set of tables that organize data into meaningful and useful units.
Q. What are the pitfalls in relational database designs?
A. The pitfalls in relational database designs are redundancy, inconsistency, and anomalies.
Q. What is normalization in the context of relational database design?
A. Normalization is the process of organizing data in a database to reduce redundancy and dependency.
Q. What is functional dependency?
A. Functional dependency is a relationship between two attributes in which the value of one attribute determines the value of another attribute.
Q. What is first normal form (1NF)?
A. First normal form (1NF) is a state of a database table that meets a minimum set of criteria including having a primary key and no repeating groups.
Q. What is second normal form (2NF)?
A. Second normal form (2NF) is a state of a database table in which all non-key attributes are dependent on the primary key.
Q. What is third normal form (3NF)?
A. Third normal form (3NF) is a state of a database table in which all non-key attributes are dependent only on the primary key and not on any other non-key attributes.
Q. What is Boyce-Codd normal form (BCNF)?
A. Boyce-Codd normal form (BCNF) is a state of a database table in which every determinant is a candidate key. It eliminates some anomalies that can occur in 3NF tables.
Q. What is a repeating group in a database table?
A. A repeating group is a set of two or more columns that are similar in nature and contain the same type of data.
Q. What are anomalies in a database table?
A. Anomalies are inconsistencies or problems that can occur in a database table, such as redundancy, deletion, and insertion anomalies.
Module 6: Transactions Management and Concurrency and Recovery
Q: What is a transaction in a database?
A: A transaction in a database is a logical unit of work that consists of a series of operations that are executed as a single unit.
Q: What are the ACID properties of a transaction?
A: The ACID properties of a transaction are Atomicity, Consistency, Isolation, and Durability.
Q: What is the meaning of Atomicity in the context of a transaction?
A: Atomicity refers to the property of a transaction that ensures that all of its operations are treated as a single, indivisible unit of work. Either all of the operations in the transaction are completed successfully, or none of them are.
Q: What is the meaning of Consistency in the context of a transaction?
A: Consistency refers to the property of a transaction that ensures that the database remains in a valid state before and after the transaction executes. The transaction must abide by all the constraints and rules of the database schema.
Q: What is the meaning of Isolation in the context of a transaction?
A: Isolation refers to the property of a transaction that ensures that its intermediate states are invisible to other transactions executing concurrently. Each transaction must execute in isolation without interference from other transactions.
Q: What is the meaning of Durability in the context of a transaction?
A: Durability refers to the property of a transaction that ensures that once a transaction has committed, its changes are permanently stored in the database, and even if there is a system failure or power outage, the changes will be preserved.
Q: What is concurrency in a database system?
A: Concurrency in a database system is the ability of multiple transactions to access the database at the same time.
Q: What is serializability in a database system?
A: Serializability in a database system is the property that ensures that the execution of multiple transactions is equivalent to some serial execution of those transactions.
Q: What are the different concurrency control protocols?
A: The different concurrency control protocols are Lock-based and Timestamp-based protocols.
Q: What is a lock-based protocol in a database system?
A: A lock-based protocol in a database system is a protocol that uses locks to prevent conflicting transactions from accessing the same data simultaneously.
Q: What is a timestamp-based protocol in a database system?
A: A timestamp-based protocol in a database system is a protocol that uses timestamps to order the transactions and ensure serializability.
Q: What is log-based recovery in a database system?
A: Log-based recovery in a database system is the process of using a log file to undo or redo transactions that were not completed due to a system failure or other error.
Q: What is deadlock handling in a database system?
A: Deadlock handling in a database system is the process of detecting and resolving deadlocks, which occur when two or more transactions are waiting for each other to release locks on resources.
Q: What are the transaction control commands in a database system?
A: The transaction control commands in a database system are COMMIT, which saves the changes made by a transaction, and ROLLBACK, which undoes the changes made by a transaction.
Some important queries