
Paper 01
Duration: 3 Hours
Total Marks: 80
Note:
- Question 1 is compulsory
- Answer any three out of the remaining five questions
- Assume any suitable data wherever required and justify the same
Questions:
Q1. (20 Marks)
- a) Explain how big data problems are handled by Hadoop system. [5]
- b) Mention four characteristics of big data and explain in detail. [5]
- c) List and explain the core business drivers behind the NoSQL movement. [5]
- d) Explain the concept of bloom filter with an example. [5]
Q2. (20 Marks)
- a) What is graph store? Give an example where a graph store can be used to effectively solve a particular business problem. [10]
- b) Write a map reduce pseudo code for word count problem. Illustrate with an example showing all the steps. [10]
Q3. (20 Marks)
- a) Suppose the stream is S = {4, 2, 5, 9, 1, 6, 3, 7}. Let hash functions h(x) = 3x + 7mod 32 for some a and b, treat result as a 5-bit binary integer. Show how the Flajolet-Martin algorithm will estimate the number of distinct elements in this stream. [10]
- b) Describe applications of data visualization. [10]
Q4. (20 Marks)
- a) Explain selection and projection relational algebraic operation using MapReduce. [10]
- b) Explain DGIM algorithm for counting ones in a stream with example. [10]
Q5. (20 Marks)
- a) Determine communities for the given social network graph using Girvan-Newman algorithm. [10]
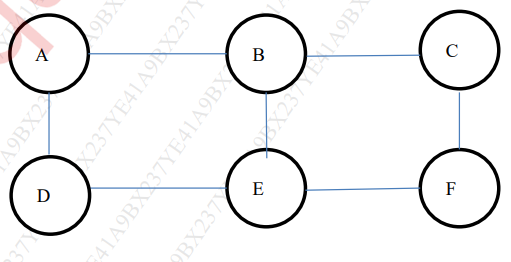
- b) Consider the following data frame:
course id class marks
1 11 1 56
2 12 2 75
3 13 1 48
4 14 2 69
5 15 1 84
6 16 2 53
i. Create a subset of course less than 5 by using [ ] brackets and demonstrate the output.
ii. Create a subset where the course column is less than 4 or the class equals to 1 by using subset () function and demonstrate the output. [10]
Q6. (20 Marks)
- a) Write a script to create a dataset named data1 in R containing the following text:
- Text: 2, 3, 4, 5, 6.7, 7, 8.1, 9
- Explain the various functions provided by R to combine different sets of data. [10]
- b) Describe collaborative filtering in recommendation system. [10]
Paper 02
Duration: 3 Hours
Total Marks: 80
Note:
- Q.1 is compulsory
- Attempt any three from the remaining
- Assume suitable data
Questions:
Q1. (20 Marks)
- a) Explain Edit distance measure with an example. [5]
- b) When it comes to big data how NoSQL scores over RDBMS. [5]
- c) Give difference between Traditional data management and analytics approach Versus Big data Approach [5]
- d) Give Applications of Social Network Mining [5]
Q2. (20 Marks)
- a) What is Hadoop? Describe HDFS architecture with diagram. [10]
- b) Explain with block diagram architecture of Data stream Management System. [10]
Q3. (20 Marks)
- a) What is the use of Recommender System. How is classification algorithm used in recommendation system. [10]
- b) Explain the following terms with diagram [10]
- Hubs and Authorities
- Structure of the Web
Q4. (20 Marks)
- a) What do you mean by Counting Distinct Elements in a stream. Illustrate with an example working of an Flajolet-Martin Algorithm used to count number of distinct elements. [10]
- b) Explain different ways by which big data problems are handled by NoSQL. [10]
Q5. (20 Marks)
- a) Describe Girwan-Newman Algorithm. For the following graph show how the Girvan Newman algorithm finds the different communities. [10]
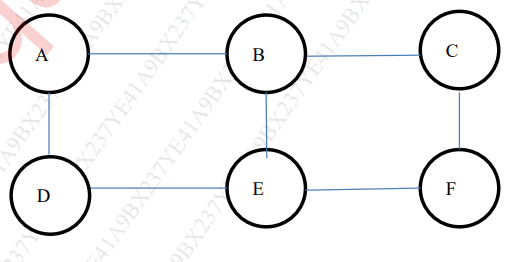
- b) What is the role of JobTracker and TaskTracker in MapReduce. Illustrate Map Reduce execution pipeline with Word count example. [10]
Q6. (20 Marks)
- a) Compute the page rank of each page after running the PageRank algorithm for two iterations with teleportation factor Beta (β) value = 0.8 [10]
- b) What are the challenges in clustering of Data streams. Explain stream clustering algorithm in detail. [10]
Paper 03
Duration: 3 Hours
Total Marks: 80
Note:
- Question 1 is compulsory
- Answer any three out of the remaining five questions
- Assume any suitable data wherever required and justify the same
Questions:
Q1. (20 Marks)
- a) Distinguish between Name node and Data node. [5]
- b) List and explain the core business drivers behind the NoSQL movement. [5]
- c) Mention four characteristics of big data. Elaborate these characteristics with respect to social media websites. [5]
- d) List and explain the different issues and challenges in data stream query processing. [5]
Q2. (20 Marks)
- a) What is a key-value store? What are the benefits of using a key-value store? [10]
- b) Write a map reduce pseudo code to multiply two matrices. Apply map reduce working to perform following matrix multiplication. [10]
1 2 6 7
x
3 4 8 9Q3. (20 Marks)
- a) Suppose the stream is S = {2, 1, 6, 1, 5, 9, 2, 3, 5}. Let hash functions h(x) = ax + b mod 16 for some a and b, treat result as a 4-bit binary integer. Show how the Flajolet-Martin algorithm will estimate the number of distinct elements, h(x) = 4x + 1 mod 16. [10]
- b) Consider the following data frame: [10]
course id class marks
1 11 1 56
2 12 2 75
3 13 1 48
4 14 2 69
5 15 1 84
6 16 2 53- i. Create a subset of course less than 3 by using [ ] brackets and demonstrate the output.
ii. Create a subset where the course column is less than 3 or the class equals to 2 by using subset () function and demonstrate the output.
Q4. (20 Marks)
- a) Explain natural join and grouping and aggregation relational algebraic operation using MapReduce. [10]
- b) With a neat sketch, explain the architecture of the data-stream management system. [10]
Q5. (20 Marks)
- a) Determine communities for the given social network graph using Girvan-Newman algorithm. [10]
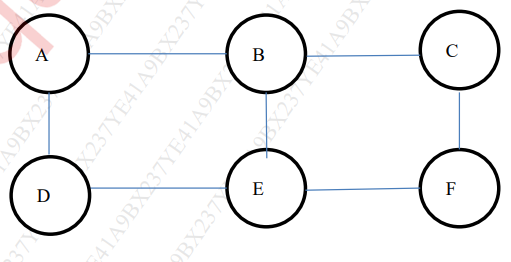
- b) List and discuss various types of data structures in R. [10]
Q6. (20 Marks)
- a) i. The following table shows the number of units of different products sold on different days: [10]
Product Monday Tuesday Wednesday Thursday Friday
Bread 12 3 5 11 9
Milk 21 27 18 20 15
Cola Cans 10 1 33 6 12
Chocolate 6 7 4 13 12
Detergent 5 8 12 20 23- Create five sample numeric vectors from this data.
- ii. Name and explain the operators used to form data subsets in R.
- b) Define collaborative filtering. Using an example of an e-commerce site like flipkart or amazon describe how it can be used to provide recommendation to users. [10]
