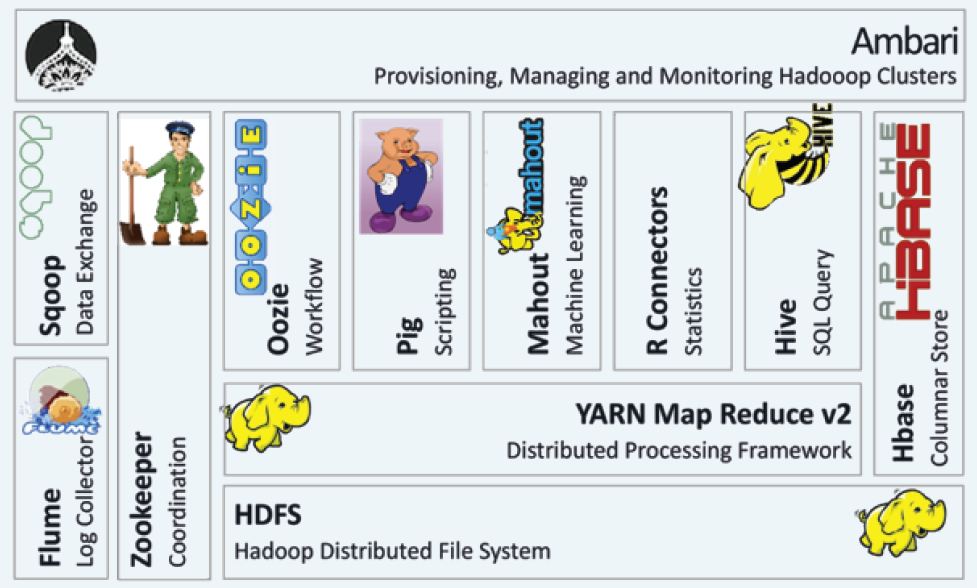
1. HDFS (Hadoop Distributed File System)
- HDFS is a distributed file system that can be installed on commodity servers, making it cost-effective.
- It is designed to store large data files across multiple machines, ensuring data reliability and availability.
- Key Feature: Fault tolerance through data replication, meaning data is duplicated across multiple nodes to prevent loss if any node fails.
2. YARN (Yet Another Resource Negotiator)
- YARN, also known as MapReduce V2, is a framework responsible for resource management and job scheduling in a Hadoop cluster.
- It manages computational resources within the cluster and allocates resources for various applications, supporting multiple data processing engines (e.g., MapReduce, Spark).
- Key Feature: It enables efficient resource allocation, which improves performance and scalability of data processing tasks.
3. Flume
- Flume is a service designed for collecting, aggregating, and transporting large volumes of log data into Hadoop.
- It’s primarily used for gathering log data from various sources and transferring it into HDFS or other storage systems.
- Key Feature: Reliable data flow, with fault-tolerant mechanisms to ensure log data reaches its destination.
4. ZooKeeper
- ZooKeeper is a coordination service that helps manage distributed applications by enabling reliable coordination across cluster nodes.
- It provides essential services like configuration management, synchronization, and naming, ensuring that applications work in unison.
- Key Feature: High reliability and consistency, essential for maintaining the state of distributed systems.
5. Sqoop (SQL-to-Hadoop)
- Sqoop is a tool for efficiently transferring data between Hadoop and relational databases or other data stores (e.g., Hive, HBase).
- It’s widely used for importing data from relational databases into HDFS and exporting data from HDFS back to databases.
- Key Feature: Simplifies data interchange between structured data sources and Hadoop, automating much of the data transfer process.
6. Oozie
- Oozie is a workflow scheduling system for managing and coordinating Hadoop jobs.
- It supports complex workflows that involve multiple Hadoop jobs, including non-MapReduce tasks.
- Key Feature: Orchestration and scheduling of tasks, allowing for complex, interdependent data processing workflows.
7. Pig
- Pig is a high-level scripting framework initially developed at Yahoo! that provides a language called Pig Latin.
- It allows users to write complex data transformations and execute them on a Hadoop cluster, simplifying MapReduce operations.
- Key Feature: Easy-to-use scripting for data processing, abstracting away much of the complexity of traditional MapReduce programming.
8. Mahout
- Mahout is a scalable library for machine learning and data mining.
- It includes algorithms for clustering, classification, and collaborative filtering, which are essential for processing large datasets.
- Key Feature: Designed to scale with Hadoop, enabling users to implement machine learning at a large scale.
9. R Connectors
- R Connectors are used within Hadoop to perform statistical analysis on cluster data.
- They integrate the statistical programming language R, allowing users to apply statistical models to data stored in Hadoop.
- Key Feature: Statistical analysis and visualization, leveraging R’s capabilities for data science tasks within Hadoop.
10. Hive
- Hive is an open-source data warehousing solution that enables querying and analyzing large datasets stored in Hadoop.
- It uses a SQL-like language called HiveQL, allowing users to write queries similar to SQL for data analysis.
- Key Feature: Provides a familiar SQL interface for Hadoop, making it easier for analysts to query big data.
11. HBase
- HBase is a column-oriented, non-relational (NoSQL) database that runs on top of HDFS.
- It supports real-time read and write access to large datasets, making it suitable for applications that need quick access to large amounts of data.
- Key Feature: Real-time data access on Hadoop, making it a preferred choice for interactive applications.
12. Ambari
- Ambari is a tool for provisioning, managing, and monitoring Hadoop clusters.
- It offers a graphical user interface (GUI) that simplifies managing Hadoop services, tracking system health, and performing administrative tasks.
- Key Feature: Cluster management and monitoring, providing administrators with a user-friendly way to oversee Hadoop operations.
Ajink Gupta Answered question